Misconfiguration Identification Rule
What is the misconfiguration identification rule?
In ETM, the misconfiguration data is imported from various external sources. It's expected to encounter overlapping information, such as identical control technology with asset context for a given misconfiguration. To avoid importing duplicate data sets, the system uses specific identification attributes of the Common Data Model as identifiers. The Misconfiguration Rule contains predefined conditions. Each condition specifies identification attributes that serve as an identifier to uniquely identify the misconfiguration regardless of the source from which it's coming in. These pre-defined conditions use the following identification attributes:
- Policy Name, Title, Technology Name
- Title, Technology Name
- Vendor ID, Technology Name
- Title
- Vendor ID
- Source Finding ID
How does the rule get executed?
When importing data from each source, the system evaluates identifiers in the chronological condition order shown in the following image. The identification evaluation stops after a match is found.
The following image illustrates the order of the predefined conditions:
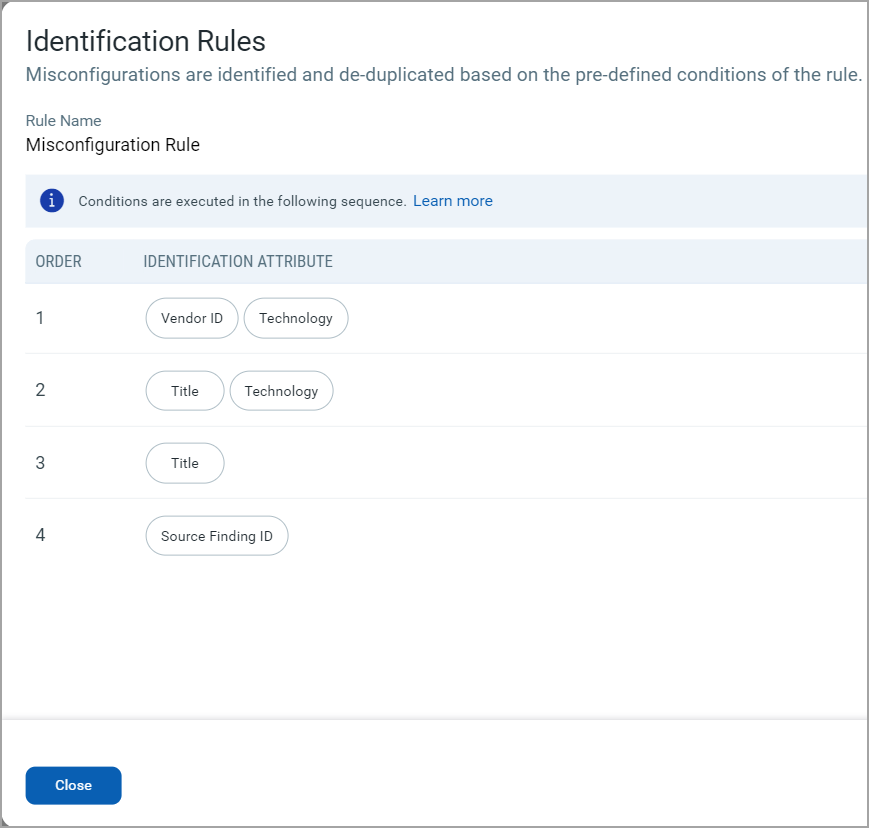
- If the control technology/ title of the incoming record matches those of an existing misconfiguration on the same asset, the system consolidates the incoming record with the existing misconfiguration record and proceeds to the next record.
- If the control technology/ title is not present for the asset, the system creates a new misconfiguration record and assigns an ETM Finding ID.
- If the identifier attribute is empty or missing from the incoming record, then the system assesses the next identifier in a similar manner, and so on.
- If none of the identifiers yield a match, then the system creates a new vulnerability record.